
Quick Notes: Variation of GAN (Stacked GAN, StackGAN++, PA-GAN)
Published:
For the past 4 months, I have been working on cardiovascular disease risk prediction. Through this, I come up with an idea to utilize GAN to learn in a progressive way and decide to write a paper on this topic(Sry, I can’t talk much about my idea in details). Then, I began doing background research and found three related topic. In this post, I will give summarizations of these topic.
Stacked(or progressive) GAN is kind of a new topic, related paper has been published starting from 2016 ( plz feel free to leave msg, if you know other related paper which is earlier than 2016, or you know other related interesting topics). The existing related research can be divided into 2 groups, one is to build the model structure hierarchically, e.g. Stacked GAN, StackGAN++, the model architecture resembles stacking(ensemble learning). The other is controlling the input to be imported in a progressive way. For PA-GAN, the input has been gradually augmented by increasing the sample dimensionality to increase task difficulty of D.
Table 1.
| Paper(Topic) | Publication Year | Goal |
|---|---|---|
| Stacked GAN | 2017 | generate high-quality image |
| StackGAN++ | 2018 | generate high-resolution photo image |
| PA-GAN | 2019 | stablize training process |
GAN
There are a lot of excellent blogs explaining the principles of GAN (e.g. From GAN to WGAN). So I won’t cover related details in this post. Before explaining the 3 GAN variations, I’d like to recall the shortcomings of GAN.
Disadvantages of GAN
Choosing which to win? The training process can be viewed as a competition between Generator(G) and Discriminator(D): iterations of attack and defend. Through such process, both the ability of G and D has been enhanced. In my opinion, this can’t reach a win-win situation. Imagine if G & D runs in a pretty tight race, then neither the simulated results of G would be of high-quality, nor the identification ability of D would be good enough. So there must be a winner between the two. Whether to choose G over D or in the opposite way, I think it depends on the specific goal of the project.
Unstable training process and vanishing gradient: I think these two are somehow correlated. The support of real data and generated ones usually lie on low dimensional manifolds and are usually disjoint –> D often learns much faster than G –> Its loss function gradient quickly becomes 0, meaning it can’t provide accurate and continuous feedback to G. That’s how these two problems come out. One solution is to enforce the model learning in a progressive process, can be viewed as controlling the learning speed, which is the main idea in the following 3 paper.
Mode collapse: GAN has been mainly used for generating high quality simulated images, but its generations are usually limited within certain scope, meaning G can’t produce diverse results.
Tips: the reason to input a random noise z to G is that z can alleviate mode collapse to certain extent, because of its randomness. (Plz correct me, if I’m not right.)
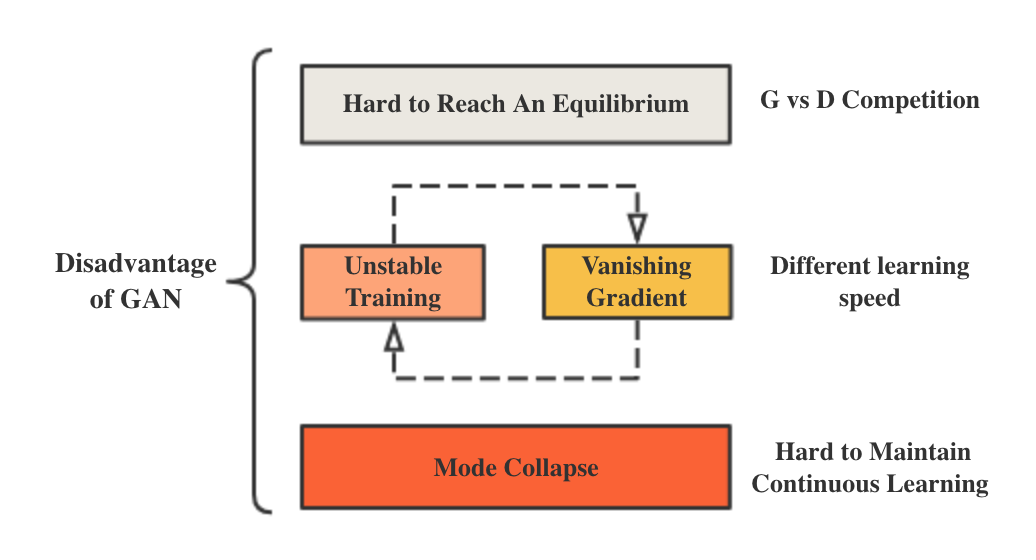
Figure 1. Disadvantages
Stacked Generative Adversarial Networks, SGAN
SGAN aims to generate high-quality image. To me, the idea of SGAN is quite brilliant. Because instead of learning the whole data directly, it hierarchically extracts information from the data through encoders, generate representation level by level, then let G learns these representation in a top-down way. From my perspective, high-level image representation contains more details than low-level ones. So G can generate more realistic and specific low-level samples based on high-level representation. Also, by importing data level-by-level, I think this can control the speed of D’s learning speed, which is helpful for stablizing the training process. These are all personal opinions, plz correct me, if something is wrong. Thx :)
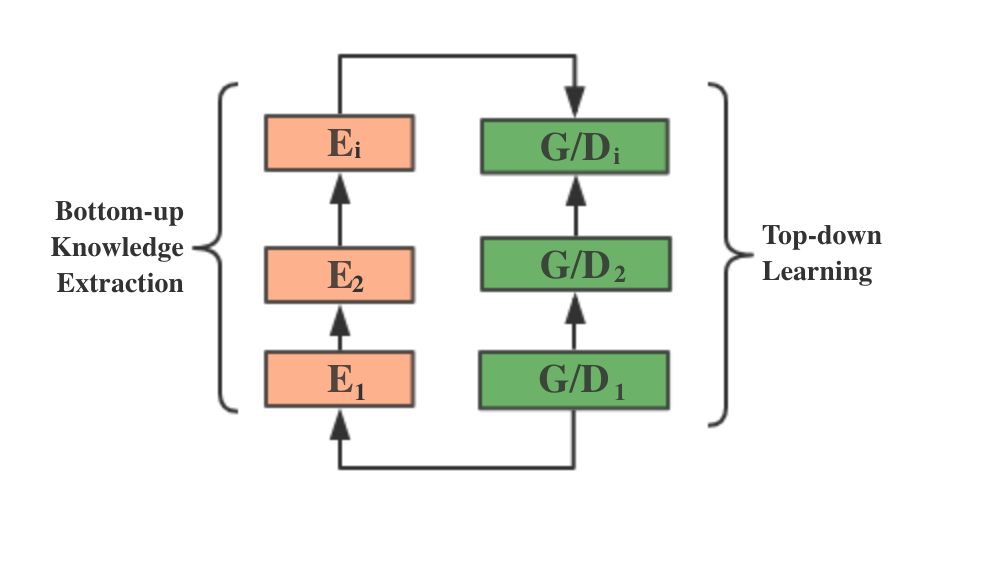
Figure 2. SGAN Framework
Next, I will dive into details of SGAN. The training stage can be divided into 3 sections, which is shown in Table 2. The first stage is to use encoders(CNN in this paper) to extract level-wise information from images in a bottom-up direction. The 2nd step is to independently training each Gi to predict level-wise representation , by taking a noise vector zi and higher level representation hi+1 as input, and let Di judge the quality of
.
Attention: the higher level feature hi+1 is the outcome of encoder Ei. To ensure indeed masters the knowledge in hi+1, a conditional loss has been introduced(shown in Table 2).
Finally, here comes with the 3rd training stage: jointly training. All Gs have been connected in a top-to-bottom direction, forming an end-to-end architecture. Each G produce an intermediate representation and then pass it to the next G as an input. So here .
Besides, it is stated in the paper that simply adding the conditional loss indeed ensures Gi learns from hi+1, but Gi tends to ignore the random noise zi. So how to avoid this? Let’s first recall the reason for adding z.
It is used to increase diversity in results. So we want to be as diverse as possible when conditioned on hi+1, which is equivalent to maximize a conditional entropy
to check if
is sufficiently diverse when conditioned on hi+1. That’s why a entropy loss has been added. (More details are articulated in the original paper, section 3.4)
Table 2.
| Training Step | Formula Details | Loss Function | Why Using This Loss Function |
|---|---|---|---|
| 1. Encoders learn level-wise intermediate representations from bottom to top(Fig 3. left blue section, arrow direction) |  | ||
| 2. Independent training of each G(Fig 3. central section) | 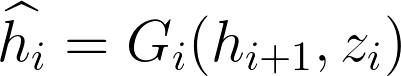 | Conditional loss: 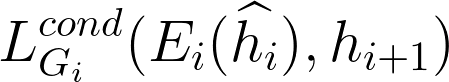 | Impose G to learn high-level conditional representation |
Adversarial loss: 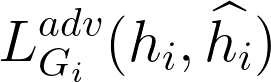 | Discriminator identify real data hi and generated ones | ||
| 3. Jointly end-to-end training of all Gs(Fig 3. central section, top to bottom, arrow direction) | 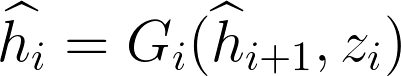 | entropy loss:  | Maintain diverse generations |
| Testing Step | Maintain Results Diversity | ||
| Top-to-bottom generating simulated images, no info. needed from encoder(Fig 3. right section) | By adding random noise z to each level |
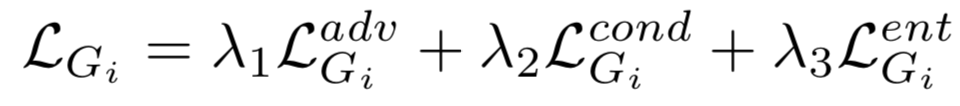
Figure 3. SGAN Final Loss Function(Source: [1])
N: # stacks, hi: level-wise representation, x: input images, h0 = x, y: classification label, hN = y, Ei, Gi, Di: the ith encoder, generator, discriminator
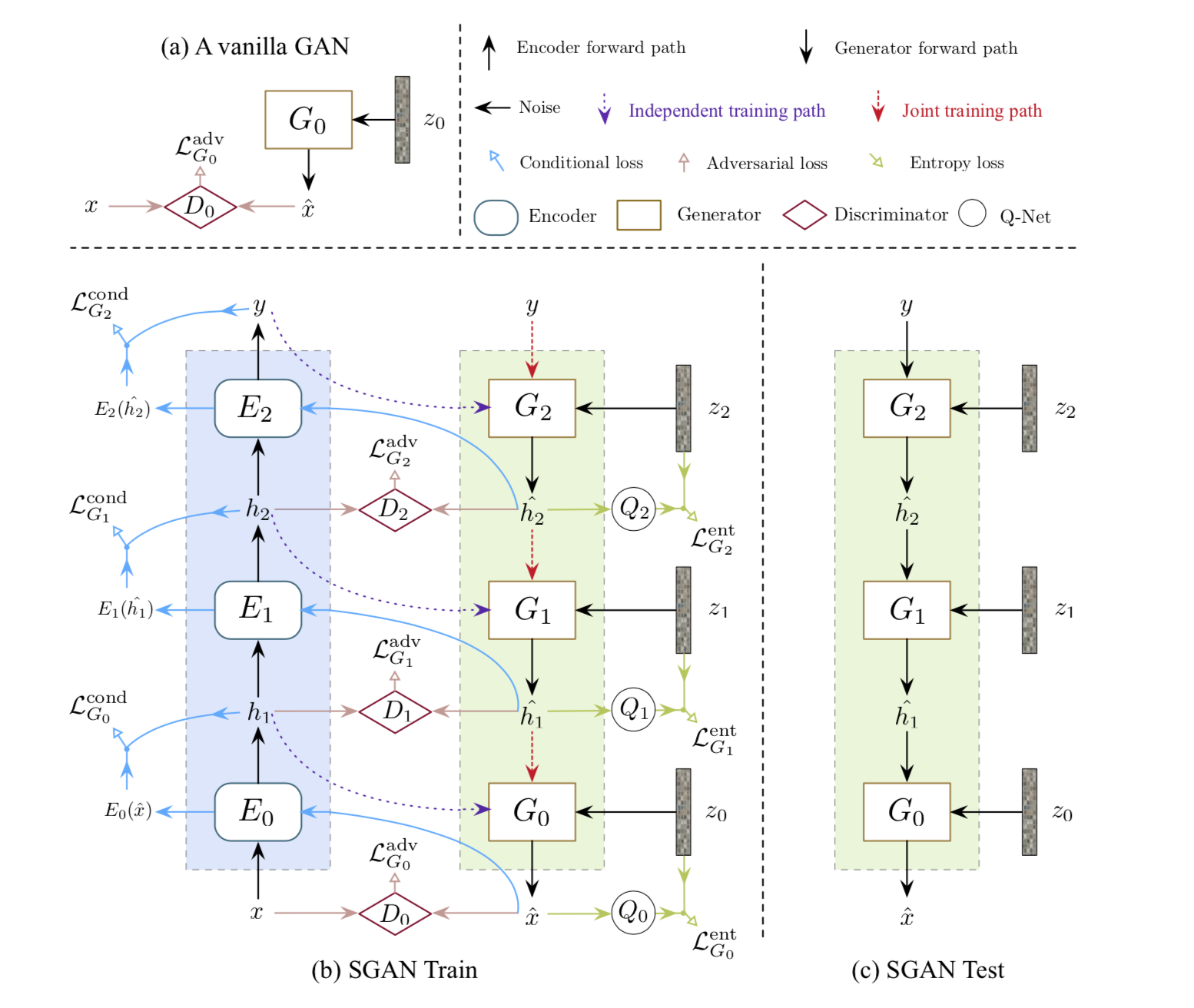
Figure 4. SGAN Framework Details(Source: [1])
StackGAN++
TBA…
PA-GAN
TBA…
Reference
[1]. Xun H., Yixuan L. et al. Stacked Generative Adversarial Networks, CVPR(2017)
[2]. SGAN Github Repo
[3]. https://medium.com/@jonathan_hui/gan-stacked-generative-adversarial-networks-sgan-d9449ac63db8
[4]. Han Zh., Tao X. et al. StackGAN++: Realistic Image Synthesis with Stacked Generative Adversarial Networks
[5]. PA-GAN: Improving GAN Training by Progressive Augmentation

Leave a Comment