
Quick Notes: Summarization about Current NER Methods in Deep Learning
Published:
Recently, I have been working on NER projects. As a greener, I have spent a lot of time in doing research of current NER methods, and made a summarization. In this post, I will list my summaries(NER in DL), hope this could be helpful for the readers who are interested and also new in this area. Before reading, I assume you already know some basic concepts(e.g. sequential neural network, POS,IOB tagging, word embedding, conditional random field).
Introduction
NER stands for name entity recognition, which aims to find the crutial objects(the entities) from text. Traditional methods are usuallt statistical models, e.g. conditional random field(CRF), hidden markov model(HMM), which requires heavily on feature engineering, and very domain-specific, which means these traditional models need large amount of hand-crafted features and may not be able to fit in new domain.
With the revival of deep learning models, now the popular methods in NER becomes DL(CNN/RNN/LSTM/GRU)+CRF/HMM. Because DL requires no feature engineering, have long dependency(sequential NN). Moreover, DL models are actually a pretty useful tool for data representation. So data would be first passed to DL, and then use the output of DL as ‘features’ to train the traditional statistical model. In this sense, the model depends largely on how well the DL layers can represent the data. To solve this problem, researchers utilized different embedding methods(word level/ char level, or add pretrained embedding).
Customized Input + DL + CRF
Paper: End to End Learning of Semantic Role Labeling Using Recurrent Neural Networks In this paper, the author designed an end-to-end role labeling framework, by utilizing customized word input format, using 4 bi-directional LSTM to generate data representation, then using CRF as final labeling layer.
Table 1. Model Structure
| Input | Processing Level | DL Layers | ML layers |
|---|---|---|---|
| raw text, no manual labeling, using pretrained word embedding(NLM), with customized input format | word level | 4* Bi-directional LSTM | CRF |
About Customized word input: For each word in the dataset, it contains 4 features [argu, pred, ctx-p, mr].
- ‘argu’: means the word currently being processed,
- pred: refers to the predicate word,
- ctx-p: shows the surrounding words to the pred,
- mr tells whether the argu is within ctx-p area to that pred.
The left part in Figure 1 shows the example used in this paper.
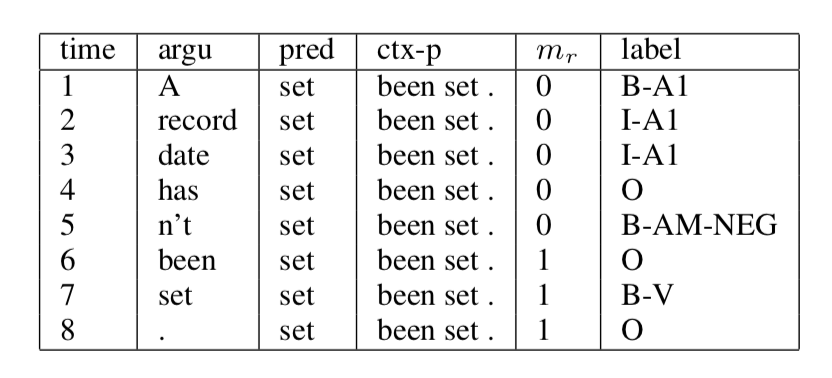
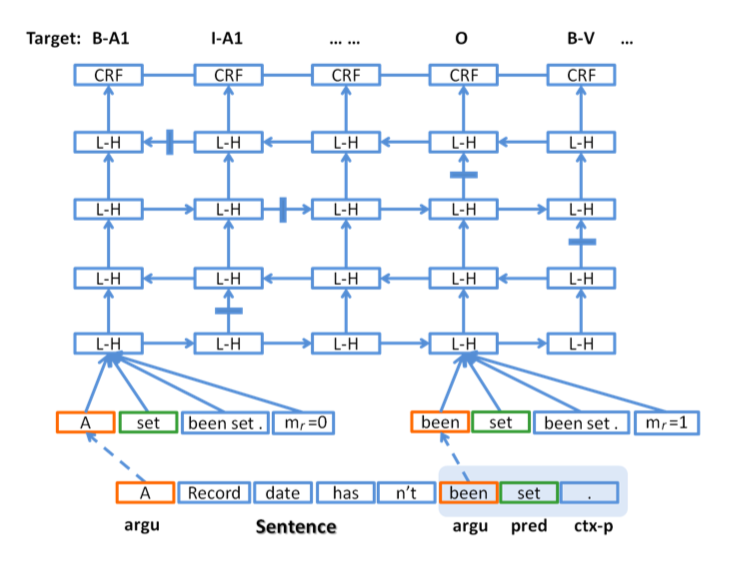

Figure 1. Customized Text Input Format and Model Topology with LSTM/CNN
The author also tried replace LSTM with CNN, with adding a fifth part to the previous four-component input format(ctx-a: context of argu). To be more specific, every four-component input has been passed into hidden unit, then add this hidden unit together with mr into the next layer hidden unit. In my opinion, they added a fifth part: the ctx-a to input, is because CNN can't handle long dependency as well as LSTM
(CNN->Char-level representattion + Word-level) Input + DL + CRF
Paper: End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF
In this paper, the author argues existing sequence labeling tasks, though achieved good performance, still need rely on info(e.g. word spelling, capital pattern) to augment their results. Especially when coming across with rare words, pre-trained embedding will probably not work well. In this sense, carrying the info about capitalization, prefix or suffix will be more helpful. In this paper, the author combines char-level and word-level representation together, enables the model to be truly free from feature engineering or pre-trained embedding and task-domain(but in section 4.4, it’s stated that NER task with pre-trained word embedding will have better performance than using random embedding).
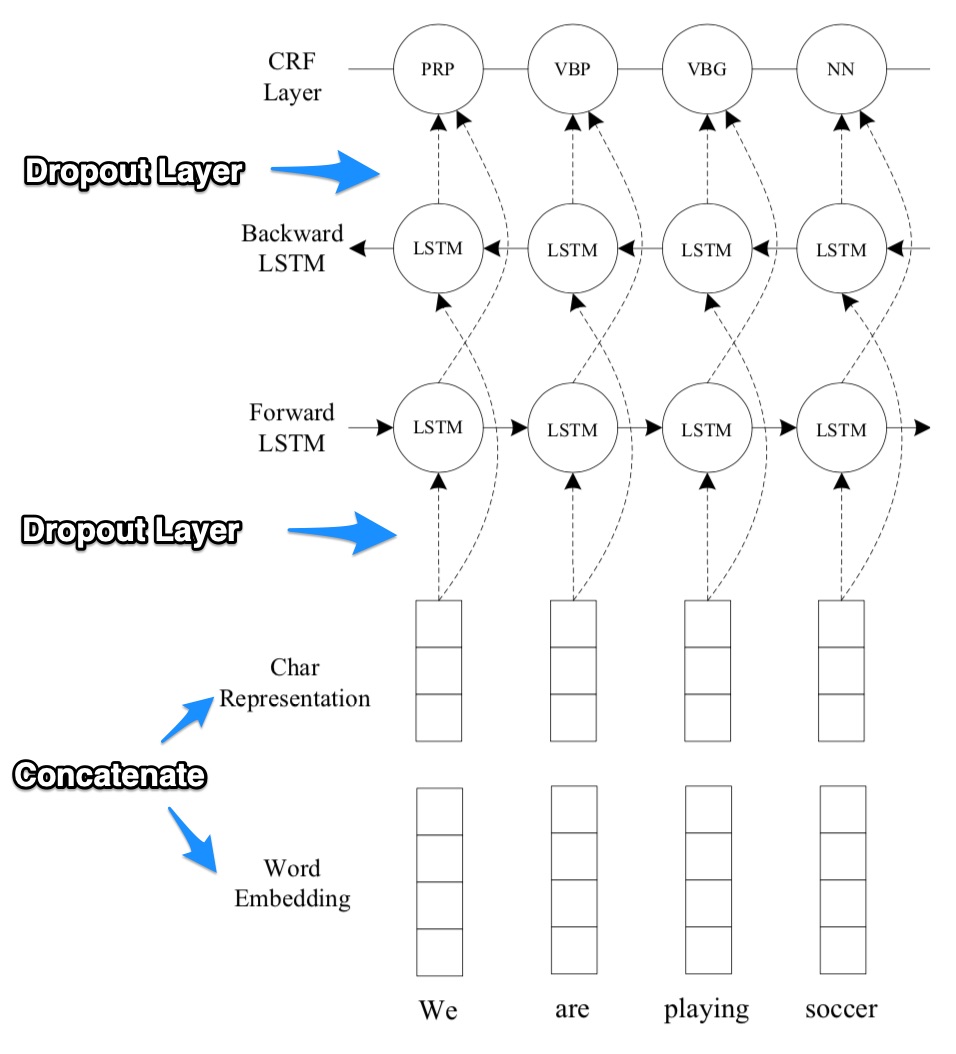

Figure 2. Model Topology and Char Representation Layer Structure
(LSTM+CRF) & (Transition-based Approach + Stacked-LSTM)
Paper: Neural Architectures for Named Entity Recognition
In this paper, the authors stresses two points.
- name entity is usually containing multiple tokens, so jointly tagging is important.
- a name usually shows orthographic evidence(what does the name look like?) and distributional evidence(where tend to be appeared in a corpus?) (distributional sensitivity is captured by using char-based word representation model)
Two model frameworks have been tested, one is LSTM+CRF, the other is transition-based chunking model. For both models, they utilize the same input embedding strategy, which maintains spelling sensitive and word order sensitive, dropout training has also been added to prevent the model depending too much on one representation.( These two sensitive features exist in various language system, so such features ensure this model would be suitable for many different languages.)
Figure 3 shows the embedding topology: gathering char-level info in both forward and backward order by using bi-LSTM. Details: 1) char lookup table will be initialized at random, containing every char, 2) as LSTM has bias towards to the most recent inputs, forward LSTM for representing suffix of the word, backward LSTM for prefix, 3) previous model use CNN for char-embedding, convnets are designed to find position invariant features, so it works well on image recognition, while for prefix, suffix, stem in words, I think these are relatively more flexible than edges/objects in a image, so I would vote for LSTM against CNN for doing char embedding.
The final step is deriving word embedding from a lookup table, then concatenating these two parts together.
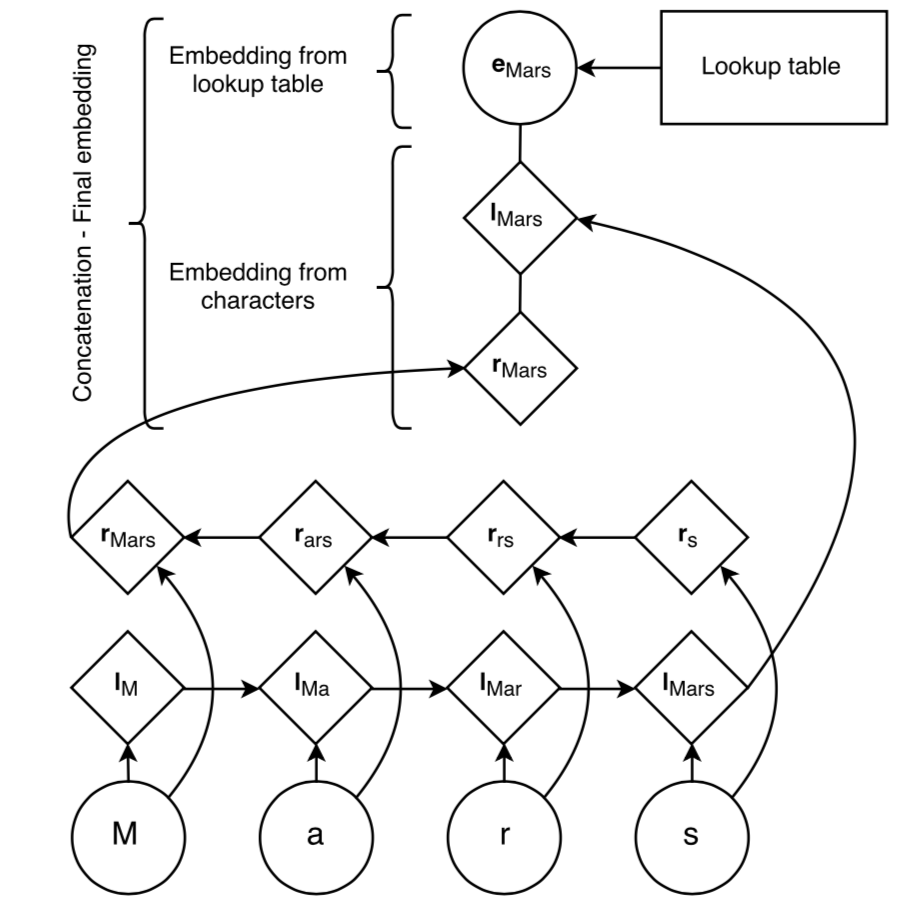
Figure 3. Input Word Embedding
Then let’s go back to the model architecture: LSTM+CRF is shown in the left part in Figure 4. Firstly, applying pretrained embedding, then passing each word into both forward LSTM layer and inversed LSTM layer, concatenating the results from these 2 layers(thus both the left and right context of the word will be obtained), finally passing the output to CRF model.(The process is relatively similar to the ones I have introduced before.)
About the transition model: name entity tends to have multiple tokens, so the author utilizes stack structure to gradually collect the tokens –> build chunk –> pop the chunk until the building process is done. stack LSTM is suitable for such task, as it allows operation at both ends.
Object needed: two stacks, a buffer: contains words need to be processes, transition inventory: contains following transitions
Operation explanation: shift transition: moves a word from buffer to stack, out transition: moves a word from buffer to output stack, reduce(y) transition: pops all items from the top of the stack, and these items form a chunk, pushes the label of this chunk to output stack. (The process is shown in the bottom part of Figure 4, with the sentence ‘Mark Watney visited Mars’ as the example)


Figure 4. LSTM+CRF VS Transition-based Chunking Model
Summary
In summary, the trend in NER is to implement end-to-end task/language-free model, usually traditional ML models CRF/HMM are used as the final layer for tagging. Sequential NN is used to capture context info in sentences, due to its long dependency property. The key to enable the model fits for multiple tasks or languages is to find proper embedding(both char & word level) format to capture prefix/suffix, word order info, which helps generateing better word representation in the DL layer. However, if the task requires strong professional knowledge, e.g. EHR/EMR, dictionary containing relating professional terms is still needed.
To be continued…
Reference
[1].Jie Zhou, Wei Xu. End-to-end Learning of Semantic Role Labeling Using Recurrent Neural Networks, the 7th International Joint Conference on Natural Language Processing(2015), 1127-1137
[2].Xuezhe Ma, Eduard Hovy. End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF.
[3].Guillaume Lample. Neural Architectures for Named Entity Recognition

Leave a Comment