
Quick notes of privileged information
Published:
Why PI ?
In human learning, we have teachers, who master the knowledge well. Thus, being taught by the teachers, we students can quickly get to the point of that question, filter out false ones, learn very fast, and achieve good marks in the test by ourselves. That’s why PI is introduced, to help ML models learning in a more fast and accurate way on training set, and work well indepedently on testing set. So, in a normal classification paradigm, you will get a set of pair as: (xi, yi), after introducing PI, the pair will be (xi, yi*, yi)
This topic was first introduced by Vladimir Vapnik and Akshay Vashist in 2009, and updated a new mechanism to PI in 2015. In this post, I will talk about two mechanisms used in PI.
Similarity Control & Knowledge Transfer
Similarity Control
This topic has been mainly discussed in [1] by taking SVM as the example. Vladimir describes the topic as “The mechanism to control students’ concept of similarity between training examples”. The general idea is: in a seperable sample set, svm only needs to estimate n parameters of w, while in a non-seperable one, it becomes n+l (n parameters of w defines the hyperplane and l values of slacks, which belongs to high VC dimension).
In SVM+, it maps vectors x into space Z and x * into Z * , which represents the decision space and correcting (slack) space. Vladimir has changed the traditional Lagrangian function (SVM) into:
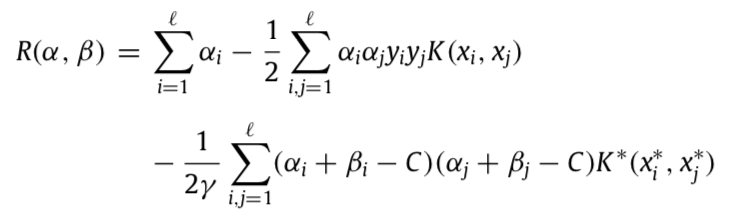
subject to constraints:
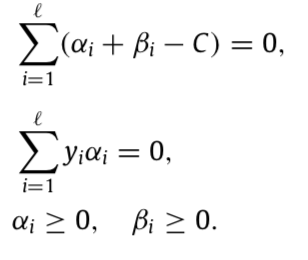
The first two items represent the separable part, the rest stands for the correcting space. Note that if αi +βi −C =0 or γ tends to 0, then the solution will be back to traditional SVM. This happens when similarity measures in Z* are not appropriate.
Knowledge Transfer
The basic idea is teacher masters rules of mapping X* to y, which is much smaller than the rules in original space X. Students need to know how to transfer useful features in X* into X. Also, as it only requires a small fraction of the entire knowledge, it doesn’t need to work on large-sized sample set.
Reference
[1]. Vladimir, V., Akshay, V. A new learning paradigm: Learning using privileged information. Neural Networks 22(2009), 544-557. doi:10.1016/j.neunet.2009.06.042
[2]. Vladimir, V., Rauf, I. Learning Using Privileged Information: Similarity Control and Knowledge Transfer. Journal of Machine Learning Research 16(2015), 2023-2049.

Leave a Comment